



前言
缓存、异步、多线程堪称高并发编程的三把利器,在高并发场景,很多接口比如商城首页banner,配置,商品列表等是用户一进入应用就会访问的,这些称为热点接口,部分接口查询逻辑比较复杂,可能会遍及多个表,如果每次访问都要请求数据库,会对数据库造成巨大的压力,当压力达到一定瓶颈时,数据库就会响应变慢甚至宕机,应用卡顿,用户体验变差,公司业务受损。这种情况下最有效的办法就是在接口层做数据缓存,接下来聊一下如何正确的实现。
几个问题
说起缓存,不得不先简单聊一下缓存穿透,缓存击穿,缓存雪崩,缓存一致性几个问题。
缓存穿透
描述: 缓存穿透是指用户请求的数据在缓存中不存在即没有命中,同时在数据库中也不存在,导致用户每次请求该数据都要去数据库中查询一遍,然后返回空。
解决办法
使用布隆过滤器。
缓存空对象。
缓存击穿
描述: 指一个非常热点的key,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个key在失效的瞬间,持续的大流量就穿破缓存,直接请求数据库,就像在一个屏障上凿开了一个洞。
解决办法
更新缓存时加锁,只允许一个线程更新。
缓存数据本身永不过期,通过额外字段设置过期时间。
缓存雪崩
描述:缓存中数据大批量到过期时间,而查询数据量巨大,请求直接落到数据库上,引起数据库压力过大甚至宕机。和缓存击穿不同的是,缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
解决办法:
设置不同过期时间。
更新缓存时加锁,只允许一个线程更新。
缓存永不过期。
缓存一致性
描述:如何保证数据库中的数据和缓存一致。
解决办法:
Cache Aside(旁路缓存)策略
写策略:先更新数据库中的数据,再删除缓存中的数据。
读策略
如果读取的数据命中了缓存,则直接返回数据。
如果读取的数据没有命中缓存,则从数据库中读取数据,然后将数据写入到缓存,并且返回给用户。
延时双删:先删除一次缓存,让数据重新从数据库加载,然后更新数据库,最后再次删除缓存。
方案
从上面内容总结下设计一个接口缓存需要考虑的点和对应解决方案
缓存穿透:和缓存正常数据一样,缓存空值即可避免。
缓存击穿:更新缓存的时候加锁,防止多个并发请求全部请求数据库。
缓存雪崩:设置缓存数据永不过期,通过额外字段控制数据刷新。
缓存一致性:
对于实时性要求较高的数据,比如商品上下架状态更新,使用Cache Aside中的写策略,在更新数据库后更新缓存中的数据。
对于实时性要求一般的数据,可以不用做更新操作,因为如果数据本身的过期时间很短,那么这块数据不一致的时间也很短,对业务来说一般是可以接受的,如果数据本身的过期时间很长,那么这项数据本身就没要求高实时性。
不能使用延时双删,会造成缓存击穿。
方案确定以后开始设计流程
分析:一般接口会有多个入参,每个参数有不同的值,不同入参返回的数据是不一样。
相关key设计:
业务入参组合:
拼接参数即可
例:
String paramKey = request.getActivityType() + request.getPageNum() + LIMITER + request.getPageSize()缓存key:
前缀 + 业务入参组合
例:
HOME_GOODS_LIST: + paramKey
缓存刷新key:
前缀 + 业务入参组合
例:
HOME_GOODS_LIST:REFRESH + paramKey
缓存刷新加锁的key:
前缀 + 业务入参组合
例:
HOME_GOODS_LIST:REFRESH_LOCK + paramKey
接口流程设计:
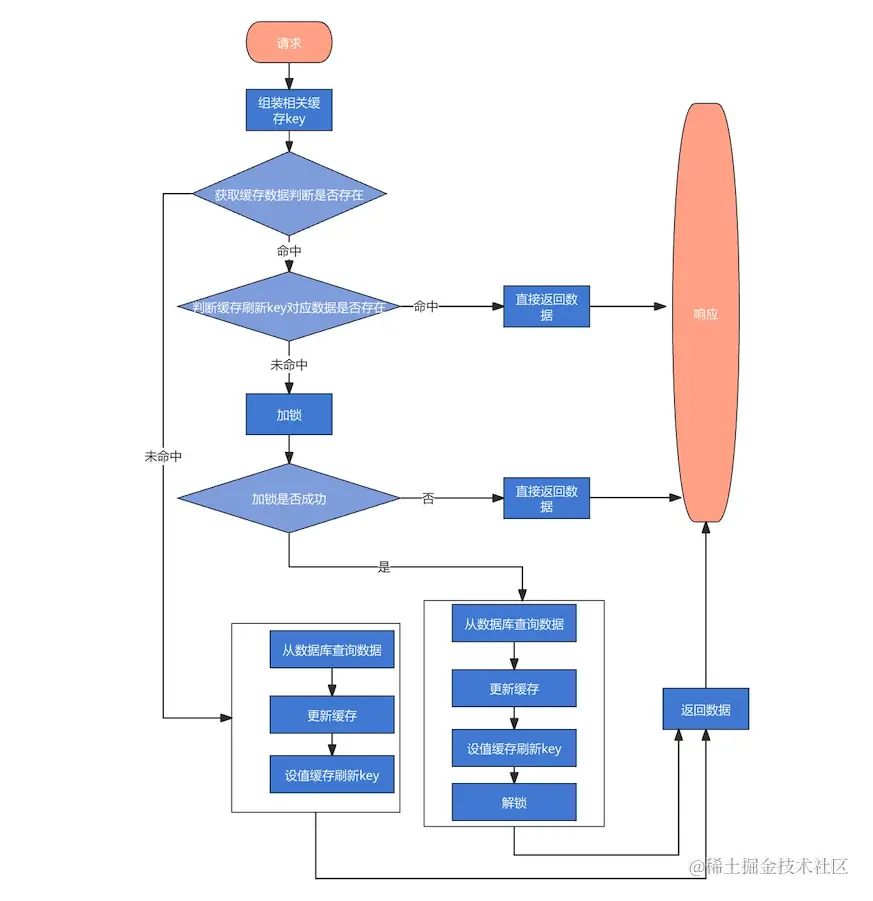
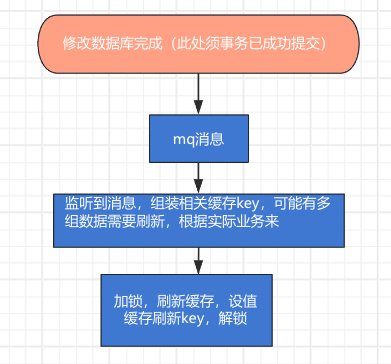
外部更新缓存数据:
样板代码如下:
public PageInfo<ComposeListResponse> composeList(DecomposeReqeuest request) {
String paramKey = SEPARATOR + request.getPageNum() + LIMITER + request.getPageSize() + LIMITER + request.getActivityType();
String composePageCacheKey = FREE_COMPOSE_LIST + paramKey;
String cacheRefreshKey = FREE_COMPOSE_LIST_REFRESH + paramKey;
String cacheRefreshLockKey = FREE_COMPOSE_LIST_REFRESH_LOCK + paramKey;
String composeListCache = redisTemplateCluster.opsForValue().get(composePageCacheKey);
PageInfo<ComposeListResponse> composeList = null;
if (StringUtils.isNotBlank(composeListCache)) {
try {
composeList = JsonUtil.parse(composeListCache, new TypeReference<>() {
});
// 判断是否需要加锁更新缓存
String cacheRefresh = redisTemplateCluster.opsForValue().get(cacheRefreshKey);
if (StringUtils.isBlank(cacheRefresh)) {
boolean locked = LockUtil.tryLock(cacheRefreshLockKey);
if (locked) {
try {
composeList = getDataFromDbAndFlushCache(cacheRefreshKey, composePageCacheKey, request);
} catch (Exception e) {
log.error("composeList cacheRefresh error", e);
} finally {
LockUtil.unlock(cacheRefreshLockKey);
}
}
}
} catch (Exception e) {
log.error("composeList to cache error", e);
}
} else {
composeList = getDataFromDbAndFlushCache(cacheRefreshKey, composePageCacheKey, request);
}
return composeList;
}
private PageInfo<ComposeListResponse> getDataFromDbAndFlushCache(String cacheRefreshKey, String composePageCacheKey, DecomposeReqeuest request) {
// 查询数据
redisTemplateCluster.opsForValue().set(composePageCacheKey, JsonUtil.json(responsePageInfo));
redisTemplateCluster.opsForValue().set(cacheRefreshKey, "1", 10, TimeUnit.SECONDS);
return responsePageInfo;
}总结
从上面的流程可以看出接口缓存实现并不复杂,只是得注意其中不同功能对应key不能用错,这种写法的优点是灵活简单,可基于实际业务做更多控制,适用于项目中需要用到缓存的接口不算很多的情况,而缺点是业务入侵性比较大,如果很多的话,可以通过Aop加自定义注解来简化写法,通过后台线程统一更新缓存,或者引入外部比较成熟的缓存框架如阿里的jetcache
支持分布式加本地两级缓存,感兴趣的伙伴可以去看看。
评论区