



引言
在人工智能发展历程中,神经网络经历了多次范式革命。从早期的感知机到传统神经网络(如CNN、RNN),再到如今的Transformer架构,每一次突破都伴随着计算范式的根本性转变。Transformer不仅重塑了自然语言处理的格局,更在计算机视觉、生物信息学等领域引发连锁反应。本文将从架构原理、计算范式、应用场景三个维度,剖析Transformer与传统神经网络的本质差异,揭示这场计算革命的深层逻辑。
一、架构革命:从空间绑定到时序解耦
1.1 感知机
感知机由美国学者Frank Rosenblatt在1957年提出,它通过接收多个输入信号,输出一个信号。比如,我们通过检查者的各项标准(血压、抽血后的各项参数、心跳心率等,多个信号)来评价这个检查者是否有疾病(有or没有,一个信号)。如图,是有两个输入的感知机。
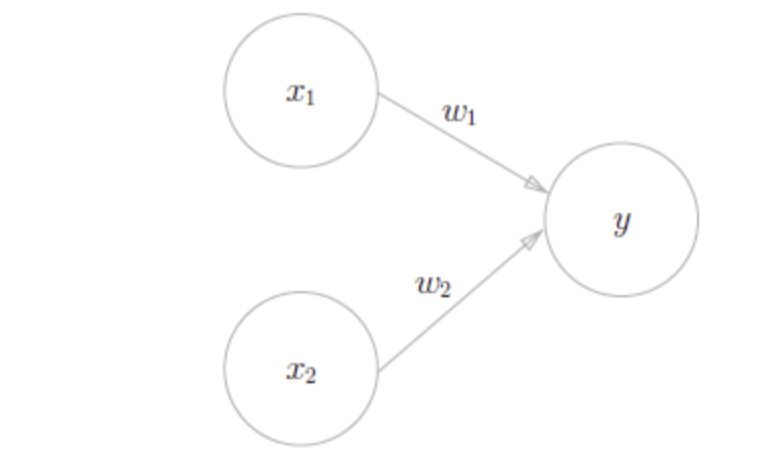
上图公式为
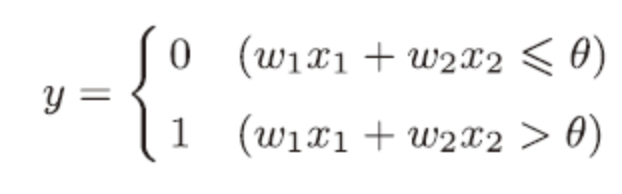
1.2 传统神经网络
神经网络其实就是多层感知机(把多个单层感知机组合在一起),再使用Sigmoid或者Tanh或Relu等平滑的非线性激活函数的多层网络,全称为人工神经网络(Artificial Neural Network,即ANN ),是一种模拟人脑神经元来建立的运算模型。
1.3 感知机、传统神经网络的时空约束
感知机感知机是一种二元线性分类器,只能做一些简单的线性二分类问题。
而传统神经网络(如RNN、CNN)受限于其架构设计:
卷积神经网络(CNN):依赖局部视野的层次化特征提取,在图像处理中表现出色,却难以建模非局部交互关系。
循环神经网络(RNN):通过时间展开实现序列建模,但梯度消失问题导致长程依赖捕获困难,且无法进行全局并行计算。
这类架构的本质缺陷在于空间与时间的强耦合:RNN将时间维度硬编码为循环结构,CNN将空间关系固化在卷积核中。这种刚性设计限制了模型对复杂模式的适应能力。
1.4 Transformer的时空解耦策略
自注意力机制:
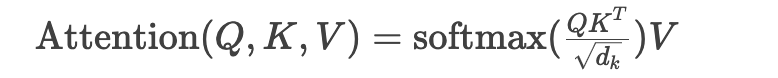
该机制使每个位置都能直接访问全局信息,突破了传统网络的局部视野限制。位置编码系统:
通过正弦函数或可学习参数将位置信息注入向量空间,实现序列顺序的显式建模,而非依赖递归结构多头注意力并行化:
将高维特征空间分解为多个子空间并行处理,在保持语义完整性的同时实现计算加速(如512维特征拆分为8个64维头)
这种设计使Transformer既能处理序列数据(如文本),又可拓展到网格数据(如图像分块),展现出前所未有的通用性。
二、计算范式:从渐进式推理到全局建模
2.1 传统神经网络的计算局限
这些架构在处理长序列时面临计算效率与建模能力的权衡困境。例如,LSTM虽缓解了梯度消失,但其门控机制的计算复杂度仍随序列长度线性增长。
2.2 Transformer的全局计算范式
Transformer通过以下方式重构计算流程:
并行矩阵运算:单次前向传播即可完成全序列关系建模,计算复杂度O(1)(不考虑softmax计算)。
残差连接架构:每个子层(注意力/前馈网络)的输出=原始输入+变换结果,有效缓解梯度衰减问题。
层次化特征融合:通过堆叠多层注意力模块,实现从局部到全局的特征抽象(如GPT-3的96层结构)。
实验表明,Transformer在处理2048长度序列时,训练速度仍比LSTM快5倍以上,同时保持更优的困惑度指标。
三、应用演进:从专用模型到通用底座
3.1 传统神经网络的应用边界
CNN主导领域:图像分类(ResNet)、目标检测(YOLO)
RNN主导领域:语音识别(DeepSpeech)、时序预测
这些架构在专用场景表现出色,但跨模态迁移能力薄弱。例如,训练好的图像分类CNN难以直接用于文本生成。
3.2 Transformer的通用智能特性
通过架构统一与模态扩展,Transformer正在重塑应用生态:
多模态统一建模
视觉Transformer(ViT):将图像拆分为16x16块序列处理,在ImageNet分类任务中超越CNN。
多模态大模型(如GPT-4):通过交叉注意力实现文本-图像-音频联合建模。
零样本推理能力
Transformer通过prompt工程实现任务自适应,无需微调即可完成翻译、摘要等任务(如ChatGPT的In-context Learning)。跨领域知识迁移
预训练-微调范式使模型参数成为通用知识载体。例如,BERT在医学文献微调后,诊断准确率提升23%。
四、挑战与未来:架构革命的未尽之路
4.1 现有架构的局限性
计算资源黑洞:1750亿参数的GPT-3单次训练耗资460万美元,碳排放量相当于5辆汽车终身排放。
序列长度瓶颈:标准Transformer的注意力矩阵内存消耗随序列长度平方增长,限制超长文本处理能力。
可解释性困境:注意力权重仅反映相关性,无法揭示因果逻辑(如医疗诊断场景的决策依据)。
4.2 下一代架构演进方向
混合架构创新
神经符号系统:结合Transformer与知识图谱,提升逻辑推理能力(如DeepMind的AlphaCode)。
状态空间模型:采用Mamba架构处理百万长度序列,突破注意力矩阵内存限制。
能效优化技术
模型蒸馏:将大模型知识迁移到小模型(如DistilBERT体积缩小40%,性能保留97%)。
动态稀疏计算:仅激活相关注意力头,降低FLOPs消耗。
生物启发式设计
脉冲神经网络融合:模拟生物神经元脉冲传递特性,提升能效比。
皮层柱状结构模拟:借鉴大脑皮层模块化组织方式,增强跨模态联想能力。
结语
Transformer架构的诞生,标志着神经网络从专用工具向通用智能基座的范式跃迁。这场革命不仅改变了算法设计逻辑,更重塑了整个AI产业的技术路线。当我们在惊叹ChatGPT的对话能力时,不应忽视其背后Transformer架构的奠基作用——它如同深度学习领域的"冯·诺依曼架构",正在成为智能时代的新型计算范式。未来的AI竞争,本质上是Transformer生态的竞争,谁能在架构创新与工程化落地的平衡中占据先机,谁就将主导下一个十年的智能革命浪潮,对于个人来说,紧跟时代脚步,我们的生活会更加多姿多彩。
评论区