



前言
近几月以来,线上应用越来越吃内存,偶有Rpc接口超时无响应,日志里出现OOM

刚开始怀疑是用户量增多(公司刚做了一批引流活动)导致,联系运维加了内存,简单有效,后面两天再没出现这问题,但到第三天左右的时候又开始了,看来公司营销做得真不错,继续加,到后面加了六七次,每次的表象和第一次几乎一样,oom虽迟但到。看来加内存解决不了根本问题。
过程
于是开始着手排查,由于日志提示得比较明显,所以思路也比较清晰,直接导出堆内存快照分析,看看是哪个大胃劳力天天掏空地主家的余粮,此次用到了以下工具
专业dump分析工具mat:https://www.eclipse.org/mat/ 利用arthas从测试环境中导出dump文件,直接拖到mat里,加载后显示overview大概是这个样子

看不出太多东西,点击Leak Suspects分析一波可能存在的漏洞,加载完成后显示如下

一开始是有点懵的,地主家是要做什么大项目,请了这么多好手,连看门大爷都是顶薪级别,属实不寻常。

让我们看看是从哪个堂口请过来的,点击右侧其中一条list objects, with outGoing references查看引用对象,如图

根据引用层级从下往上找,首先找到NioChannel类中的appReadBufHandler变量
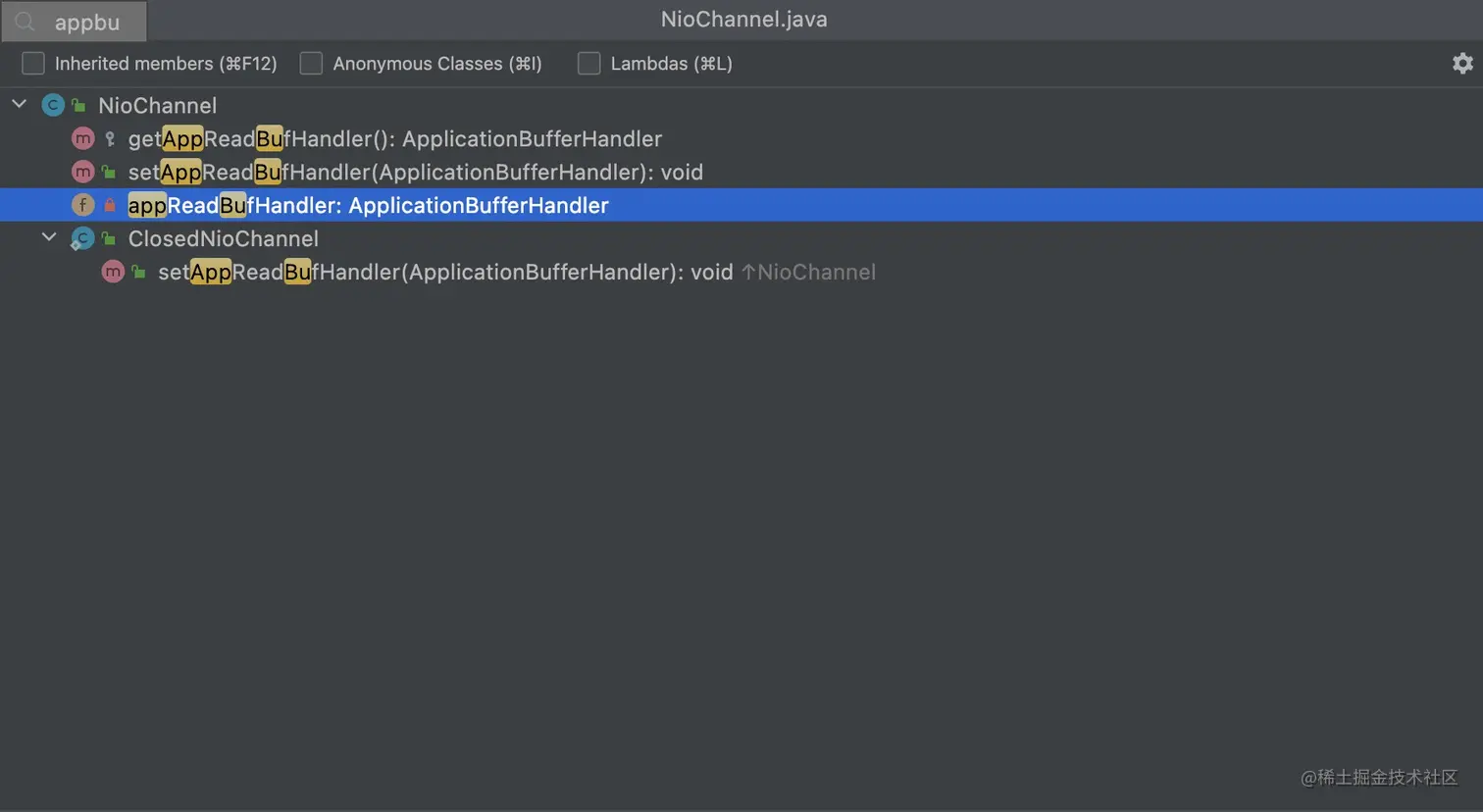
查看是在哪个位置设值, 根据set方法一层一层往上找,最后跳到了Http11InputBuffer类中

可以看到放进去的值是当前类初始化后的对象,于是寻找Http11InputBuffer初始化的地方,根据构造方法跳到Http11Processor中

可以看到比较可疑的点protocol.getMaxHttpHeaderSize(),点进去看了下字段注释

字面意思最大http头大小8*1024(B),也就是8字节, 再回到Http11InputBuffer中,从上面引用图可以看出实际占用内存的对象是其byteBuffer变量,搜了一下,就在刚刚设值的下面

一层层找下去,最后到了HeapByteBuffer中

可以看到,此处初始化了一个字节数组,而数组的容量和刚刚的maxHttpHeaderSize间接关联 再往里找,最终到ByteBuffer类中
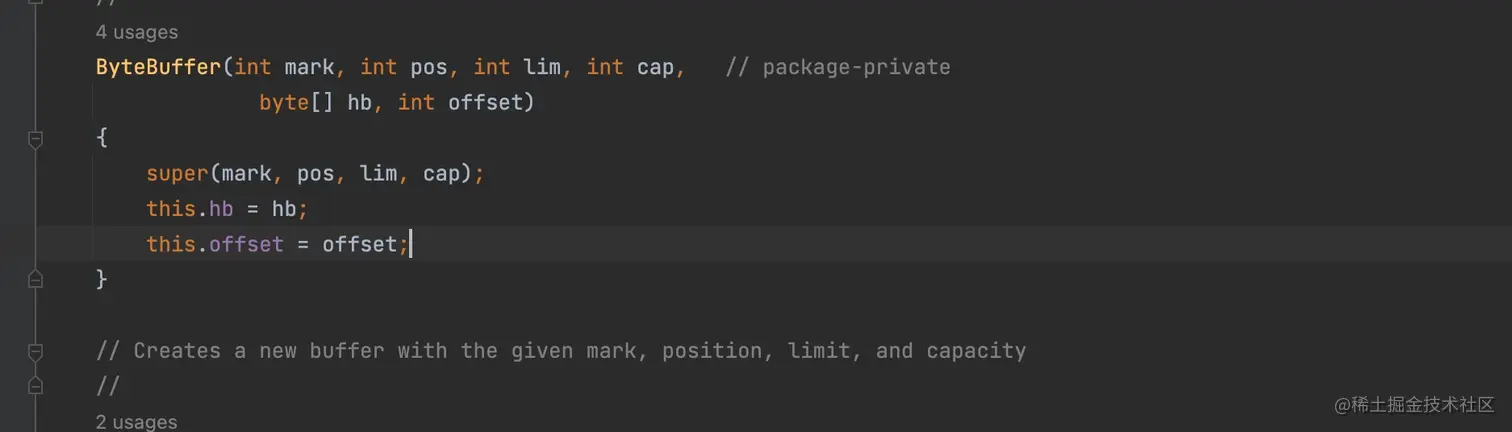
将刚刚创建的数组赋值给力hb变量,也就和上图第一层引用关系中的hb正好对应上,引用关系梳理清楚,但按理来说如果以默认给的容量初始化,强力gc加钞能机器随便他造,可实际上是不是呢,debug一看

这一看吓一跳,这么多个个0,算了下9.5M左右,相当于每一个请求都要初始化一个9.5M的字节数组,刚好和上面的对象占用匹配,再去项目里全局搜索了下有无maxHttpHeaderSize相关的配置更改,果然在application.yml文件中找到

真相大白,接下去就是解决问题,看了下提交记录,和部门同事沟通了下得知修改此配置是因为当时前端上传文件为base64形式的时候会有问题,就加了这个配置,但目前上传方式已做了修改,不再需要。 于是删除此项配置,重新debug发现初始化已恢复默认值,重新部署测试环境并特意造些流量压测,观察几天后发现不再出现oom。再看看其他项目是否有同样问题,一并修改,最后提工单重新部署生产,观察一段时间后发现内存使用恢复正常,问题算是就此解决。
总结
一些不常用的参数得慎用,在使用过后及时观测运行情况。
评论区