



为你的向量数据提速:Milvus 索引类型全解析与选择指南
在向量数据库的世界里,Milvus 无疑是一个闪亮的明星。它能够轻松处理十亿甚至万亿级别的向量数据,而其背后强大的索引和搜索能力是其核心优势之一。然而,面对 Milvus 提供的多种索引类型,很多开发者可能会感到困惑:我到底该用哪一种?
这篇博客将为你详细解析 Milvus 支持的主要索引类型,并提供一个清晰的指南,帮助你在不同场景下做出最佳选择。
为什么需要索引?
想象一下,在一个拥有十亿条向量的数据集中,用一条查询向量进行最朴素的“暴力搜索”(即计算查询向量与数据库中每一个向量的距离),其计算量是巨大的,响应速度会非常慢。索引的目的就是通过某种方式组织数据,帮助我们在不牺牲太多准确性的前提下,极大地加速搜索过程。这个过程通常被称为“近似最近邻搜索”。
Milvus 主要索引类型解析
Milvus 支持多种索引,适用于不同的数据类型(浮点型向量、二值向量)和场景。以下是几种最常用和最重要的索引:
1. FLAT (精确搜索)
工作原理:FLAT 实际上不是真正的“索引”,因为它不进行任何数据压缩或预处理。它就是简单地将所有原始向量数据加载到内存中。当执行搜索时,它会计算查询向量与集合中每一个向量的距离,然后返回最接近的结果。
优点:100% 的搜索准确率。
缺点:速度慢,内存占用高,与数据量呈线性增长。
适用场景:
数据量很小(例如,少于10万)。
要求 100% 召回率的场景,并且可以接受较慢的查询速度。
2. IVF 系列 (Inverted File)
IVF 系列索引是 Milvus 中最常用和平衡的索引之一。其核心思想是“分而治之”。
工作原理:
聚类:首先对所有向量进行聚类,生成
nlist个聚类中心(单元)。分配:将每个原始向量分配到最近的中心所属的单元中。
搜索:搜索时,先找到查询向量最接近的
nprobe个单元,然后只在这些单元内的向量中进行精确比较。
主要成员:
IVF_FLAT:原始向量被完整存储,搜索精度高,但内存占用与 FLAT 相同。IVF_SQ8:在IVF_FLAT的基础上,对每个向量进行标量化(有损压缩),将原始占 32 位的浮点数压缩为 8 位整数。这能大幅减少内存占用(约减少 70-75%),但会轻微损失一些精度。IVF_PQ:乘积量化,一种更激进的压缩方式。它在内存占用和搜索速度上表现更好,但精度损失相对较大。通常用于超大规模数据集。
适用场景:高精度、高性能要求的中大规模数据集。
IVF_SQ8是内存和性能之间一个极佳的平衡点,是许多生产环境的默认选择。
3. HNSW (Hierarchical Navigable Small World)
HNSW 是当前最流行和高效的图索引算法之一。
工作原理:它通过构建一个分层的图结构来组织数据。底层图包含所有节点,越往上节点越稀疏。搜索时,从顶层开始,快速定位到目标区域,然后逐层向下,直到底层,找到最近邻。
优点:
搜索速度极快,尤其是对低维向量。
精度非常高。
易于使用,参数直观(
ef和M)。
缺点:
构建索引的速度较慢。
内存占用非常高(甚至高于
IVF_FLAT)。
适用场景:
对查询速度要求极高的中小规模数据集。
维度不是特别高(例如,低于 1000 维)的场景。
4. 磁盘索引
当数据量过于庞大,无法全部装入内存时,Milvus 提供了磁盘索引。
工作原理:主要代表是
DISKANN。它利用 SSD 硬盘的大容量和高吞吐特性,在磁盘上构建图索引,并通过缓存和预取机制来加速搜索。优点:能够处理远超内存容量的大型数据集。
缺点:查询延迟远高于内存索引。
适用场景:十亿级以上的超大规模数据集,且对查询延迟要求不极端(通常在 10-100 毫秒级别)。
5. 标量索引:高效过滤的利器
在实际应用中,单纯的向量搜索往往不够。我们通常需要先通过一些标量条件(如分类、时间范围、标签等)过滤数据,然后在过滤后的结果集中进行向量搜索,这就是混合查询。为了加速这类查询,Milvus 为标量字段(非向量字段)提供了专门的标量索引。
Milvus 支持多种标量索引类型,用于加速对非向量字段的查询和过滤操作:
标量索引选择指南:
追求简单省心或快速原型开发:可以直接使用
AUTO_INDEX,让Milvus自动为你选择。需要应对多种查询场景:
INVERTED 索引是一个通用且可靠的选择,尤其适用于混合查询中的标量过滤。针对低基数字段进行快速过滤:例如状态、类型、标签等只有少数几个可选值的字段,
BITMAP 索引利用位运算,在多条件组合过滤时性能卓越。频繁进行字符串前缀搜索:如果你的查询条件经常是
LIKE "prefix%"这种形式,TRIE 索引是最佳选择。大量进行数值范围查询或排序:如果需要对数值或时间戳字段进行大量
>、<、BETWEEN或ORDER BY操作,可以考虑使用STL_SORT 索引。
索引选择指南:一张图搞定
面对这么多选择,你可以遵循以下决策流程:
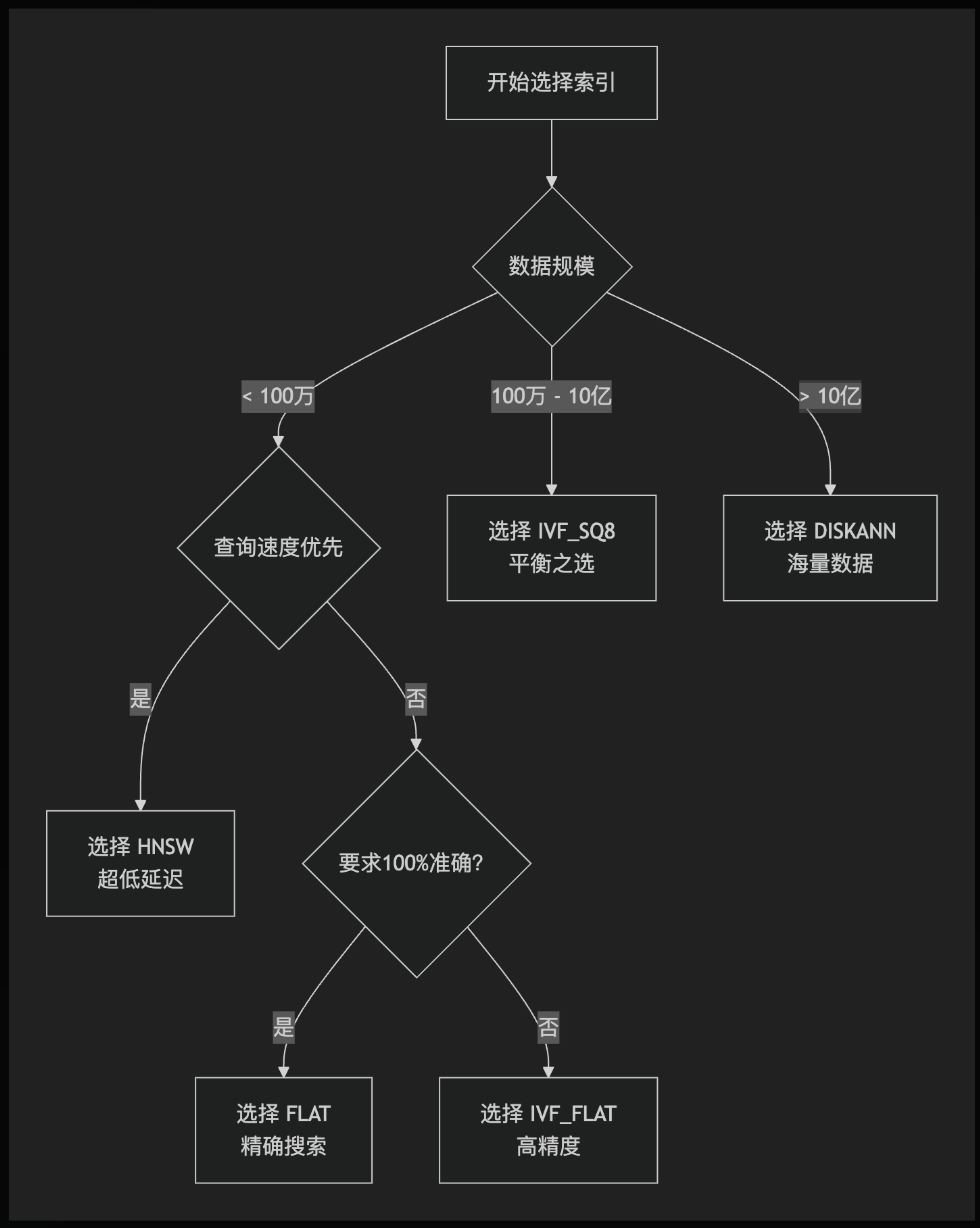
决策流程解读:
确定数据量级:
小规模 (< 100万):你有更多选择。继续判断你的核心需求。
中大规模 (100万 - 10亿):
IVF_SQ8通常是默认的最佳选择,它在内存、速度和精度之间取得了完美的平衡。超大规模 (> 10亿):
DISKANN是你的不二之选,它利用磁盘处理海量数据。
对于小规模数据:
追求极限速度:选择
HNSW。它能提供极低的查询延迟。需要 100% 准确率:选择
FLAT。这是唯一能保证完全准确的索引。追求高精度且内存充足:
IVF_FLAT在调整nprobe后也能获得接近 FLAT 的精度,且速度快于 FLAT。
重要参数调优
选择了正确的索引类型只是第一步,合理的参数配置同样关键。
IVF 索引:
nlist:聚类中心数量。值越大,单元分得越细,搜索精度可能越高,但构建越慢。通常设置为sqrt(n)(n 是向量总数)的 4~10 倍。nprobe:搜索时探查的单元数。这是搜索时最重要的参数。值越大,精度越高,速度越慢。需要在准确率和速度之间做权衡。
HNSW 索引:
M:每个节点最大连接的边数。值越大,图越稠密,精度越高,但内存占用和构建时间也增加。efConstruction:控制索引构建的质量。值越大,构建的图质量越高,构建越慢。ef:搜索时动态维护的候选队列大小。这是搜索时最重要的参数。值越大,搜索精度越高,速度越慢。
总结
没有一种索引是万能的。选择 Milvus 索引的过程,本质上是一个在内存、查询速度、查询精度和索引构建时间之间进行权衡的过程。
新手入门/小数据:从
HNSW或IVF_FLAT开始,它们简单有效。生产环境/大数据:
IVF_SQ8是经过验证的、可靠的通用选择。极致性能/低延迟:
HNSW是你的利器。成本控制/海量数据:
DISKANN让你能够用有限的硬件资源处理万亿级数据。
最好的方法是,在你的实际数据集和业务查询上进行基准测试,通过调整参数来观察性能(QPS)和准确(召回率)的变化,从而找到最适合你业务场景的“黄金组合”。
评论区